


Ever felt the frustration of wrangling with mountains of data through web scraping? The landscape of marketing technology is constantly growing and #marketing teams are experimenting with new tools that are constantly generating a tons of data. As #MarketingAnalytics professionals, we constantly juggle data from such tools and sometimes, API connectors just aren’t available ready-made from tools like Fivetran or Airbyte. In such cases, we have to rely on building a custom Python scripts to either leverage the API of that data source (which is relatively an easier option) or scrape the authenticated web pages with the help of Python libraries like BeautifulSoup and Selenium.
Python based web scraping can be a real beast to tame, especially when dealing with massive datasets and dynamic web pages.
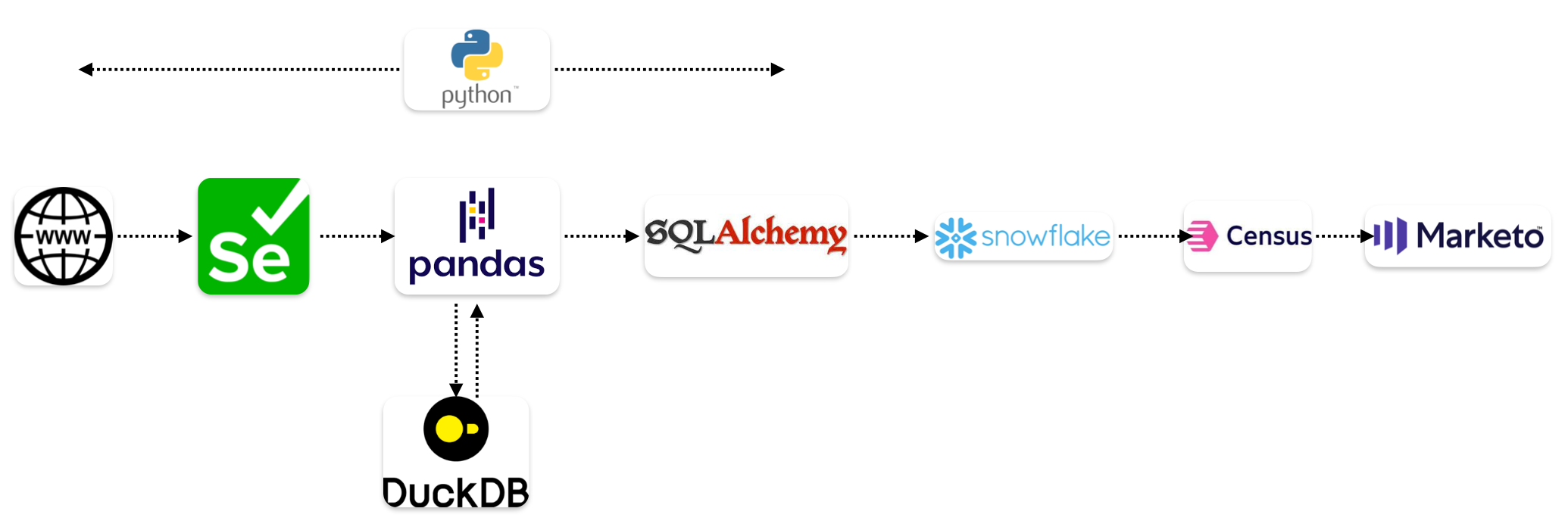
Join me on a journey where I harness the power of Python, Pandas, DuckDB, and web scraping to not just access data but to convert it into actionable data model that powers a very targeted marketing engagement strategy.
🕸️ The Challenge: Scraping a CMS Blog without an API
I recently faced this exact dilemma: scraping blog data from our CMS, which lacked an API. My trusty Python script, armed with BeautifulSoup (BS4) and Selenium, was ready for battle. Tackling the dynamic intricacies of web pages, especially in the context of pagination and the dynamic loading of client-side content (thanks to AJAX and JavaScript), posed a distinctive set of hurdles.
🛠️ Configuring UserAgent, Sessions, TLS, Referrer, and Chrome options
Setting up the basic script was a smooth sailing. The excitement kicked in when I started exploring the DOM structure of the web pages, pinpointing the specific HTML tag that housed the data I needed for this project.
The sight when any of my Python scripts first render web scraped data as list item is always such a joy and never gets old. It’s that satisfying feeling of problem solved!
driver.find_element(By.TAG_NAME, 'tbody').find_elements(By.CLASS_NAME, 'profile_groups')
load_more = driver.find_element(By.XPATH,
'//*[@id="_profilegroup"]/div[2]/div/div[2]/div/div/button')
load_more.click()
🕵️ The Webpage DOM and the “Load More” Conundrum
In this case though, the joy of seeing the first set of rows loaded was short-lived! Things got interesting as I hunted down the elusive “Load More” button, aiming to grab additional rows dynamically before I can read and store the data in a Pandas DataFrame.
Attempting to load all the data in one go turned out to be a problem, causing memory overload and web page crashes. With thousands of rows, my script started to buckle under the weight of the data.
Clearly this option of first loading all the data on the webpage and then scraping was not going to work. Traditional methods of storing everything in a Pandas DataFrame after full scraping is done or directly writing to a database like Snowflake were simply too resource-intensive.
🦆 DuckDB comes to rescue with Plan B
So, for my Plan B, I devised a strategy to leverage DuckDB. First, I would load the initial batch of rows, scrape the data, and then stash it away in storage. After that, I’d load the next batch of rows on the webpage and repeat these steps, employing 2 loops. The key differentiator in this approach was to use Pandas DataFrame with a companion, DuckDB for the iterative inserts and continuous updates.
To handle 2 different loop iterations in resonance, I had to come up with an interesting algorithm because one of the loops in my Python script was running on page load sequence but with every “Load More” click, the secondary loop was loading additional rows. These added rows were stitched onto the ongoing sequence from the very start of the webpage load, not kicking off a fresh sequence. While one loop had to kick off anew, the other needed to pick up right where the first loop had left off.
Wrapping my head around and implementing this puzzle piece turned out to be quite a delightful journey!
The mighty ‘f’ strings came to the rescue here and I could make the XPATH of the key elements dynamic – “tr[{counter + 1}]”.
if profiles:
if len(profiles[starting_point:ending_point]) > 0:
logging.info(f'beginning extraction of profile data for iteration no: {i}')
for item in profiles[starting_point:ending_point]:
# company
try:
item.find_elements(By.XPATH,
f'//*[@id="_profile"]/div[2]/div/div/div/table/tbody/tr[{counter + 1}]')
except NoSuchElementException as err:
logging.info(f'could not locate element for company on iteration no. {i}')
company = ''
else:
company = item.find_element(By.XPATH,
f'//*[@id="_profile"]/div[2]/div[2]/div/table/tbody/tr[{counter + 1}]').text
# domain
try:
item.find_element(By.XPATH,
f'//*[@id="_profile"]/div[2]/div[2]/div/div/table/tbody/tr[{counter + 1}]')
except NoSuchElementException as err:
logging.info(f'could not locate element for domain on iteration no. {i}')
domain = ''
else:
domain = item.find_element(By.XPATH,
f'//*[@id="_profile"]/div[2]/div[2]/div/table/tbody/tr[{counter + 1}]').text
This kind of algorithm and data volumes involve some serious input/output (I/O) action. Using just Pandas DataFrame to store this data incrementally in a CSV file or a database like Snowflake would burn a hole in my resources.
You see, dynamic and ongoing web scraping Python scripts have a tendency to get shaky, especially when faced with webpage refreshes and shaky internet connections. Given the hefty load of data and the repetitive looping through the loaded rows, I needed a solution to effortlessly fetch and store the data one iteration at a time, considering I had over 7500 iterations on my hands. And here’s where DuckDB stepped in!
🚀 Harnessing DuckDB for Stability in Python-Based Web Scraping
As part of my script, I initialized a DuckDB database and created a table with the relevant columns. Once a selenium iteration (as shown above) was finished successfully, I loaded the set of rows scraped into a DataFrame via a list of dictionaries. Once the DataFrame was built, I then inserted all the rows in the DataFrame into DuckDB table and clear out the DataFrame for next set of rows being scraped by Selenium Python script.
The primary objective of using this approach was to avoid the instability associated with Selenium scripts
when it comes to scraping a massive database from a dynamic (AJAX / JavaScript) based web page and avoid Snowflake credit usage associated with such I/O operations during the development cycle.
if company != '':
try:
str(company).strip()
except:
logging.info(f'company name clean-up not possible for iteration {i} and {counter}')
else:
company = str(company).strip()
try:
str(domain).strip()
except:
logging.info(f'domain name clean-up not possible for iteration {i} and {counter}')
else:
domain = str(domain).strip()
try:
str(title).strip()
except:
logging.info(f'title clean-up not possible for iteration {i} and {counter}')
else:
title = str(title).strip()
extract.append(
{
'company': company,
'title': title,
'domain': domain
}
)
logging.info(f'successfully extracted data for profile no: {counter + 1}')
counter += 1
logging.info(f'successfully finished extraction for all profiles data for iteration no: {i}')
else:
logging.info(f'no profiles found in the iteration no: {i}')
if len(contact_extract) > 0:
df = pandas.DataFrame(data=extract)
load_duckdb(df)
logging.info(f'successfully loaded set no: {i} into duckDB.')
In the realm of such Python web scraping scripts that stretch over hours,
custom Python logs emerged as unsung heroes, not only in keeping tabs on the script’s ongoing status but also proving handy when things go south,
and Python scripts decide to play hide and seek with errors. In a project-first, I opted to store these logs in a separate JSON file, just for the fun of it.
If only, I could do the same with SQL CTEs!
🧹 Seamless Data Transition and Cleanup in Pandas
After finishing up the scraping process, I effortlessly brought all the data back from DuckDB into a DataFrame with just one line of code.
From there, it was business as usual, employing the familiar tools of Pandas to tidy up and normalize the data. While I would like to handle all the data cleanup and normalization within DuckDB (or Polars for that matter) someday, I’m currently relishing the benefits of blending the best of both worlds.
💰 Optimizing Snowflake Costs with Python-DuckDB Alchemy
After the data was transformed, I turned to SQLAlchemy to seamlessly dispatch it to a Snowflake table. Once settled in Snowflake, the next step involved
transferring this dataset to Marketo, a move facilitated by a Reverse ETL process utilizing Census.
Throughout this entire process, especially in the development cycle, it marked the first instance where I had to tap into Snowflake credits.
🌐 The Power and Promise of DuckDB
Cost optimization is currently a key focus for every organization when it comes to Snowflake, and instances like these showcase how Python, coupled with the prowess of an OLAP database like DuckDB (harnessing the unlimited power of M2 Macs), can play a vital role. While I had been casually experimenting with DuckDB for some random testing use cases,
DuckDB’s robustness, simplicity, and particularly its Python API and integration with Pandas blew me away.
This implementation served as my inaugural semi-professional venture with DuckDB, as it’s not a script in constant motion via AirFlow or Prefect. Excited to delve deeper into leveraging DuckDB for more such use cases involving extensive development iterations and massive data I/O operations.
🤝 Join the Conversation
Have a similar use case or challenges to share? I’m eager to dive into new data frontiers. Let’s exchange insights and push the boundaries of what Python, Pandas, and DuckDB can achieve in the dynamic landscape of #MarketingAnalytics.